
2026年1月2日Luke
Caret NotebookLM: Solar 100Bの疑惑を通して見る、真のソブリンAIとオープンソースの未来
UpstageのSolar 100Bモデルをめぐる技術的な議論を通して、真のソブリンAIの進むべき道と、信頼できるAIコンパニオンとしてのCaretの視点から見たオープンソースによる公開検証の重要性を探ります。
最近、韓国のAIコミュニティは、UpstageのSolar 100Bモデルをめぐる技術的な議論で盛り上がっています。このモデルが中国のオープンソースモデルから派生したという主張が出てきたことで、技術的な検証の重要性がこれまで以上に高まっています。

この議論は、単一の企業のモデルにとどまらず、私たち全員に重要な問いを投げかけています。真の**「ソブリンAI」**とは何か、そしてグローバルなオープンソースエコシステムとの健全な連携が不可欠なのはなぜか? Upstageによる透明性のある回答の約束と、コミュニティの自発的な参加は、健全な技術的議論の場を開き、国内AIエコシステムの集団的な成長を促進しています。
このトピックをより深く掘り下げるために、私たちCaretは、Caret Notebook LMを使用して2つの動画を制作しました。
- 概要:
- 議論:
どちらの動画も、当社のオープンソースプロジェクトであるNotebookLM to YouTubeを使用して作成されました。関連ニュースは、Caretのブログを通じて引き続き共有していきます。
Caretの視点:信頼できるAIコンパニオンに向けて
もちろん、Upstageのような大規模なモデルを構築する企業と、まだ第一歩を踏み出したばかりの私たちのようなスタートアップを直接比較することは困難です。率直に言って、この話題の火中の栗を拾おうとしているだけのように見えるかもしれません。😅
しかし、「AIコンパニオン」の作成者として、またAIを日常的に使用する開発者として、この議論は私たちにとって異なるレベルで共鳴します。これは、AI技術、特にソブリンAIの進歩にとって「信頼」と「透明性」がどれほど重要であるか、そしてコミュニティを通じた公開検証プロセスが健全な技術エコシステムをどのように育成できるかの好例となります。
これこそが、Caretが安定性が証明されたオープンソースのClineに基づいて「共進化するAIコンパニオン」を夢見ている理由です。AIが開発者にとって最も親しい同僚となるためには、何よりも信頼できる存在でなければなりません。その信頼は、ソースコードを開示し、コミュニティと共に進化し、継続的な検証を受けるという透明性の高いプロセスを通じてのみ確固たるものとなります。
この議論が非生産的な紛争を超越し、Upstageの公開検証へのコミットメントのように、国内AIエコシステム全体が透明性と開放性の価値を再確認し、共に成長する機会となることを願っています。オープンソースコミュニティの一員として、Caretも健全な技術エコシステムに貢献するツールと文化の創造に努めます。
【放送後レビュー】「ログ」がすべての疑惑を証明に変えた方法
Upstageの技術検証放送を通じて、以前のすべての疑惑が明確なデータとログによって裏付けられました。放送の全編は元のリンクで視聴できます。
開発者として、放送で提示された主要な証拠の要約を以下に示します。なぜそれが決定的な証拠となったのか、そして当初の批判が技術的な誤解から生じた理由を説明します。
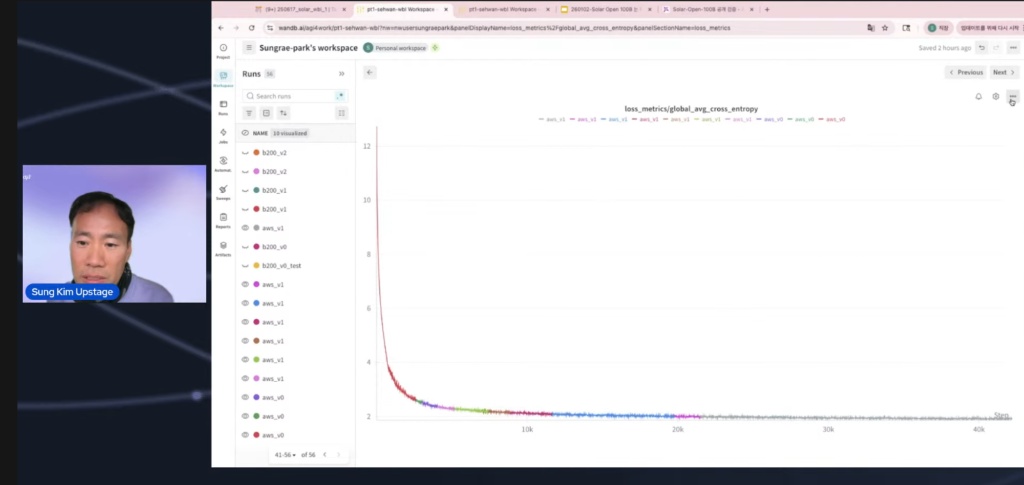
- 決定的な証拠:「From Scratch」を確認するWandBトレーニングログチャート 最も強力な証拠は、モデルのトレーニングプロセス全体を記録および視覚化した**「WandBトレーニングログチャート」**でした。公開されたチャートには、Loss値が最初のチェックポイントから12で始まり、その後急激に低下する曲線が明確に示されていました。
これが意味すること:事前トレーニングされたモデルからチェックポイントをインポートしてファインチューニングした場合、初期損失がこれほど高くなることはありえません(通常は2〜3程度から始まります)。
論争の中心は、「From Scratch」の定義でした。多くの人がこの基準に混乱していたため、放送はそれを明確にすることから始まりました。トレーニングを白紙の状態から開始すると、必然的に初期損失が非常に高くなることが明確にされました。

証拠として、実際のトレーニングプロセスを記録したWandBダッシュボードのスクリーンショットが公開されました。下の画像は、初期Loss値が非常に高いところから始まっていることを示しており、モデルが白紙の状態から学習を開始したという強力な物理的証拠となっています。
- 「類似性」の罠:大きさではなく、方向を見る 疑惑の発端となった「コサイン類似度」が、なぜ欠陥のある指標であったかも実証されました。
指標の限界:コサイン類似度は、ベクトルの**「方向」**のみを考慮します。同じアーキテクチャ(設計図)を使用した場合、ベクトルの方向は、レイヤーの構造的特性により類似する傾向があります。
実際の比較:要素ごとに重みを確認すると、スケールと特定の数値が完全に異なっていました。「全員が北極星を指しているからといって、同じ懐中電灯であるとは限らない」という事実が確認されました。
(余談ですが、下の画像には、当時のUpstageの会話のスニペットが含まれています。ちょっとした「イースターエッグ」のようです。😅)


- 構造的な差別化:「コピー」ではなく「改善」
構造的な特徴も明確に説明され、単純な複製ではないことが示されました。
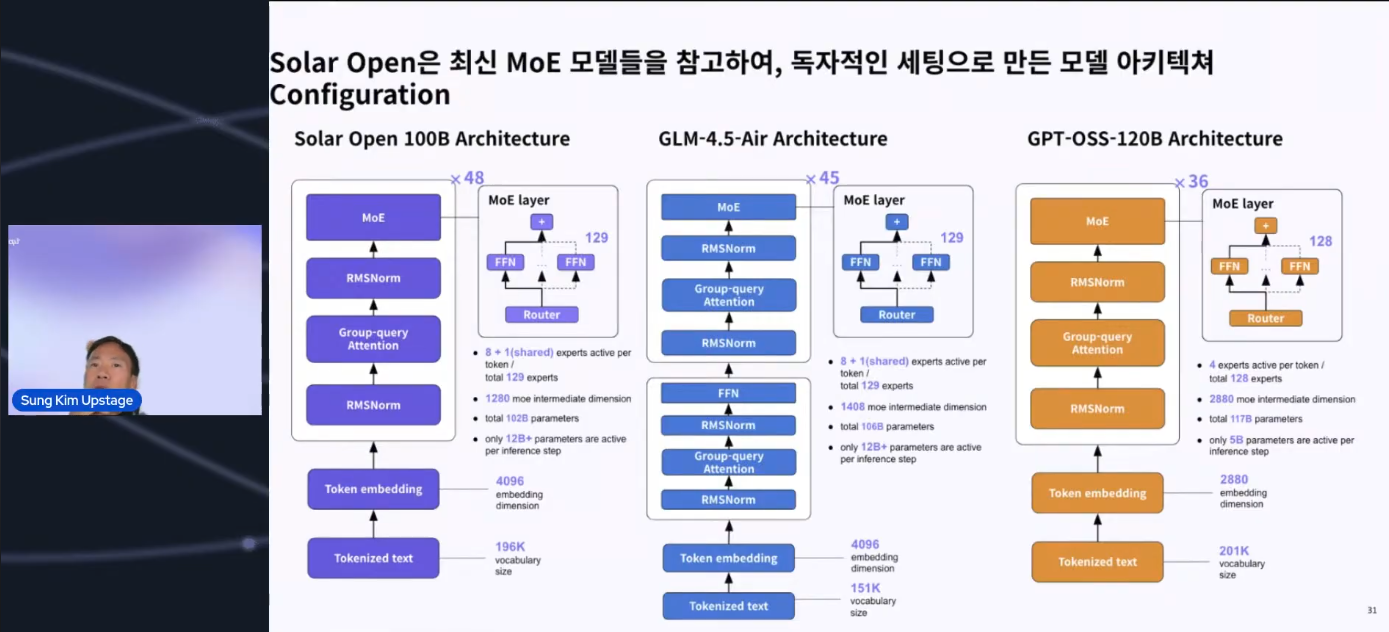 GPT-OSS 120Bとの違い:安定したトレーニングのためにShared Layersを追加することで構造が強化されました。
GPT-OSS 120Bとの違い:安定したトレーニングのためにShared Layersを追加することで構造が強化されました。
GLMとの違い:パフォーマンスにほとんど影響を与えないと判断されたDense Layersを大胆に削除するなど、独自のエンジニアリング上の決定と最適化が行われたことが確認されました。
結論 この明確化は、感情的な訴えではなく、データ、ログ、アーキテクチャによって証明されたため、開発者コミュニティに大きな信頼性をもたらしました。結局のところ、「コードは嘘をつかない」という真実を再確認する瞬間となりました。
More posts

Type next instructions while AI is streaming, cancel with a single ESC press. Also includes Gemini 3.1 Pro Support, Direct VSIX Download, CLI sub-agent execution, and v0.4.7 infinite loading fix.
Careti v0.4.7でZ.AI GLM-4.7モデル、Claude Code互換コマンドシステム、SmartEditEngine改善、UI改善を追加しました。