
2. Jan. 2026Luke
Caret NotebookLM: Die Zukunft von Sovereign AI und Open Source durch die Solar 100B Vorwürfe
Durch die technische Diskussion um Upstages Solar 100B Modell untersuchen wir den Weg für echte Sovereign AI und die Bedeutung von Open-Source-öffentlicher Verifizierung aus der Perspektive von Caret als vertrauenswürdiger KI-Begleiter.
In letzter Zeit war die koreanische KI-Community von technischen Diskussionen rund um Upstages Solar 100B Modell begeistert. Nachdem Behauptungen aufkamen, dass das Modell von einem chinesischen Open-Source-Modell abgeleitet wurde, ist die Bedeutung der technischen Verifizierung wichtiger denn je geworden.

Diese Debatte geht über das Modell eines einzelnen Unternehmens hinaus und wirft uns allen eine entscheidende Frage auf: Was macht echte 'Sovereign AI' aus und warum ist eine gesunde Allianz mit dem globalen Open-Source-Ökosystem unerlässlich? Upstages Versprechen einer transparenten Antwort und die freiwillige Teilnahme der Community haben ein Forum für eine gesunde technische Debatte eröffnet und das kollektive Wachstum des heimischen KI-Ökosystems gefördert.
Um tiefer in dieses Thema einzutauchen, haben wir von Caret zwei Videos mit dem Caret Notebook LM produziert.
- Überblick:
- Diskussion:
Beide Videos wurden mit unserem Open-Source-Projekt NotebookLM to YouTube erstellt. Wir werden weiterhin verwandte Nachrichten über den Caret Blog teilen.
Carets Perspektive: Auf dem Weg zu einem vertrauenswürdigen KI-Begleiter
Natürlich ist es schwierig, ein Unternehmen, das riesige Modelle wie Upstage baut, direkt mit einem Startup wie unserem zu vergleichen, das gerade seine ersten Schritte unternimmt. Offen gesagt, könnte es sogar so aussehen, als würden wir nur versuchen, auf den Zug dieses brisanten Themas aufzuspringen. 😅
Als Schöpfer eines "KI-Begleiters" und als Entwickler, die täglich KI nutzen, berührt uns diese Diskussion jedoch auf einer anderen Ebene. Sie dient als Paradebeispiel dafür, wie wichtig "Vertrauen" und "Transparenz" für den Fortschritt der KI-Technologie, insbesondere Sovereign AI, sind und wie ein öffentlicher Verifizierungsprozess durch die Community ein gesundes Technologie-Ökosystem fördern kann.
Genau deshalb träumen wir bei Caret davon, einen "sich mitentwickelnden KI-Begleiter" auf der Grundlage des stabilitätsgeprüften Open-Source Cline zu schaffen. Damit eine KI zum engsten Kollegen eines Entwicklers werden kann, muss sie vor allem vertrauenswürdig sein. Dieses Vertrauen kann nur durch einen transparenten Prozess der Offenlegung des Quellcodes, der Weiterentwicklung mit der Community und der kontinuierlichen Verifizierung gefestigt werden.
Wir hoffen, dass diese Diskussion über unproduktive Streitigkeiten hinausgeht und, wie Upstages Engagement für die öffentliche Verifizierung, zu einer Gelegenheit für das gesamte heimische KI-Ökosystem wird, die Werte Transparenz und Offenheit zu bekräftigen und gemeinsam zu wachsen. Als Mitglied der Open-Source-Community wird sich Caret auch bemühen, Werkzeuge und eine Kultur zu schaffen, die zu einem gesunden technologischen Ökosystem beitragen.
[Post-Broadcast Review] Wie 'Logs' alle Anschuldigungen in Beweise verwandelten
Durch Upstages technischen Verifizierungssendung wurden alle vorherigen Anschuldigungen mit klaren Daten und Protokollen untermauert. Sie können die vollständige Sendung unter dem Original-Link ansehen.
Hier ist eine Zusammenfassung der wichtigsten Beweise, die in der Sendung präsentiert wurden, die erklärt, warum sie entscheidend waren und wie die anfängliche Kritik auf einem technischen Missverständnis beruhte.
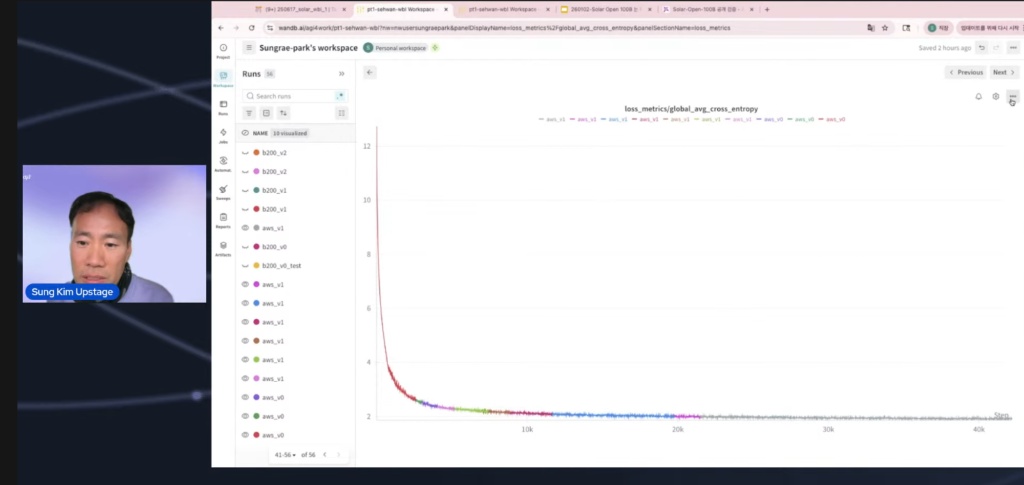
- Entscheidender Beweis: WandB Training Log Charts bestätigen 'From Scratch' Der stärkste Beweis war das 'WandB Training Log Chart', das den gesamten Modelltrainingsprozess aufzeichnete und visualisierte. Das öffentlich geteilte Diagramm zeigte deutlich eine Kurve, bei der der Loss-Wert von Anfang an bei 12 begann und dann stark abfiel.
Was das bedeutet: Wenn sie durch den Import eines Checkpoints aus einem vortrainierten Modell feinabgestimmt hätten, hätte der anfängliche Verlust nicht so hoch sein können (er beginnt normalerweise bei etwa 2-3).
Der Kern der Kontroverse war die Definition von 'From Scratch'. Da viele von diesem Standard verwirrt waren, begann die Sendung mit der Klärung. Es wurde klargestellt, dass der Beginn des Trainings von einem leeren Blatt zwangsläufig zu einem sehr hohen anfänglichen Verlustwert führt.

Als Beweis enthüllten sie einen Screenshot des WandB-Dashboards, das den tatsächlichen Trainingsprozess aufzeichnete. Das Bild unten zeigt, dass der anfängliche Loss-Wert sehr hoch beginnt, was ein starker physischer Beweis dafür ist, dass das Modell von einem leeren Blatt aus zu lernen begann.
- Die "Ähnlichkeits"-Falle: Blick auf die Richtung, nicht auf die Größe Es wurde auch gezeigt, warum 'Cosine Similarity', der Ausgangspunkt der Anschuldigungen, eine fehlerhafte Metrik war.
Einschränkung der Metrik: Die Kosinusähnlichkeit berücksichtigt nur die 'Richtung' von Vektoren. Wenn die gleiche Architektur (Blaupause) verwendet wird, sind die Vektorrichtungen aufgrund der strukturellen Eigenschaften der Schichten zwangsläufig ähnlich.
Tatsächlicher Vergleich: Bei der elementweisen Untersuchung der Gewichte waren die Skala und die spezifischen numerischen Werte völlig unterschiedlich. Es bestätigte die Tatsache, dass "nur weil sie alle zum Polarstern zeigen, bedeutet das nicht, dass sie die gleiche Taschenlampe sind".
(Als lustige Randbemerkung enthalten die Bilder unten einen Ausschnitt aus Upstages damaliger Konversation, wie ein kleines "Osterei". 😅)


- Strukturelle Differenzierung: Eine 'Verbesserung', keine Kopie
Auch strukturelle Merkmale wurden klar erläutert, die zeigten, dass es sich nicht um ein einfaches Duplikat handelte.
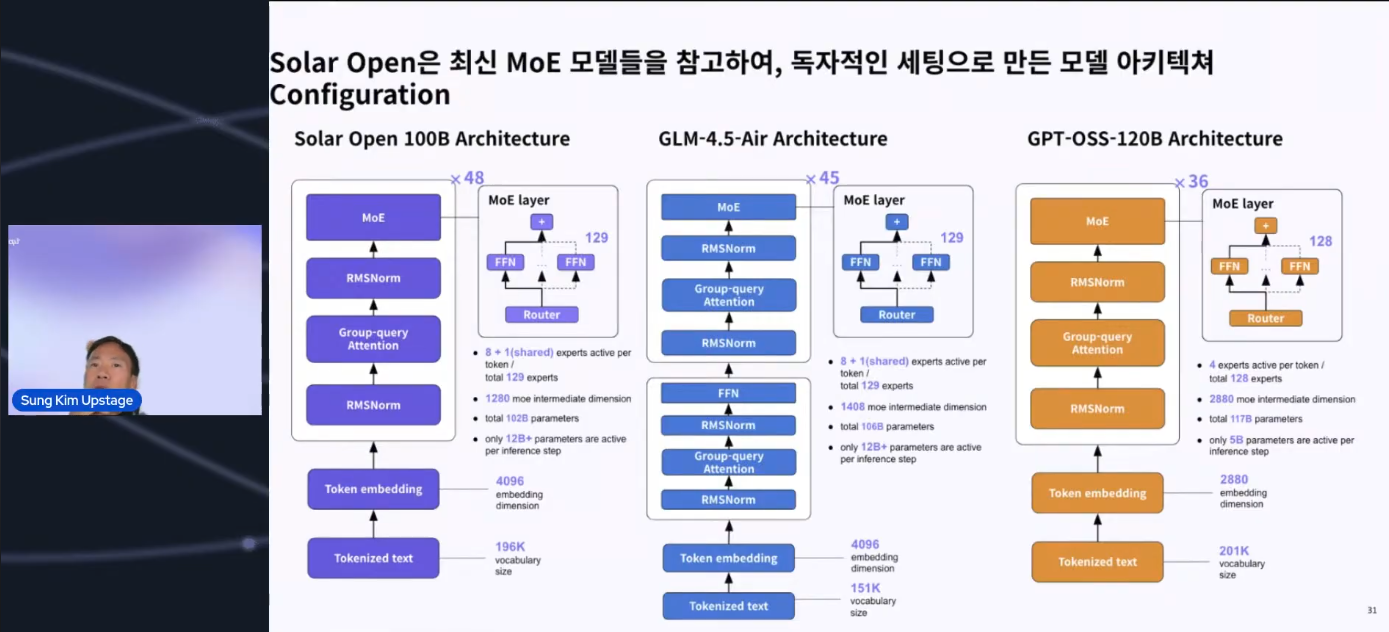 Unterschiede zu GPT-OSS 120B: Die Struktur wurde durch Hinzufügen von Shared Layers für ein stabiles Training verstärkt.
Unterschiede zu GPT-OSS 120B: Die Struktur wurde durch Hinzufügen von Shared Layers für ein stabiles Training verstärkt.
Unterschiede zu GLM: Es wurde bestätigt, dass unabhängige technische Entscheidungen und Optimierungen vorgenommen wurden, wie z. B. das mutige Entfernen von Dense Layers, die als wenig leistungsbeeinträchtigend angesehen wurden.
Fazit Diese Klarstellung verlieh der Entwickler-Community große Glaubwürdigkeit, da sie nicht mit emotionalen Appellen, sondern mit Daten, Protokollen und Architektur bewiesen wurde. Am Ende war es ein Moment, der die Wahrheit bekräftigte, dass "Code nicht lügt".
Weitere Beiträge

Type next instructions while AI is streaming, cancel with a single ESC press. Also includes Gemini 3.1 Pro Support, Direct VSIX Download, CLI sub-agent execution, and v0.4.7 infinite loading fix.
Careti v0.4.7 fügt das Z.AI GLM-4.7 Modell, Claude Code kompatibles Befehlssystem, SmartEditEngine Verbesserungen und UI-Erweiterungen hinzu.